모델 및 환경
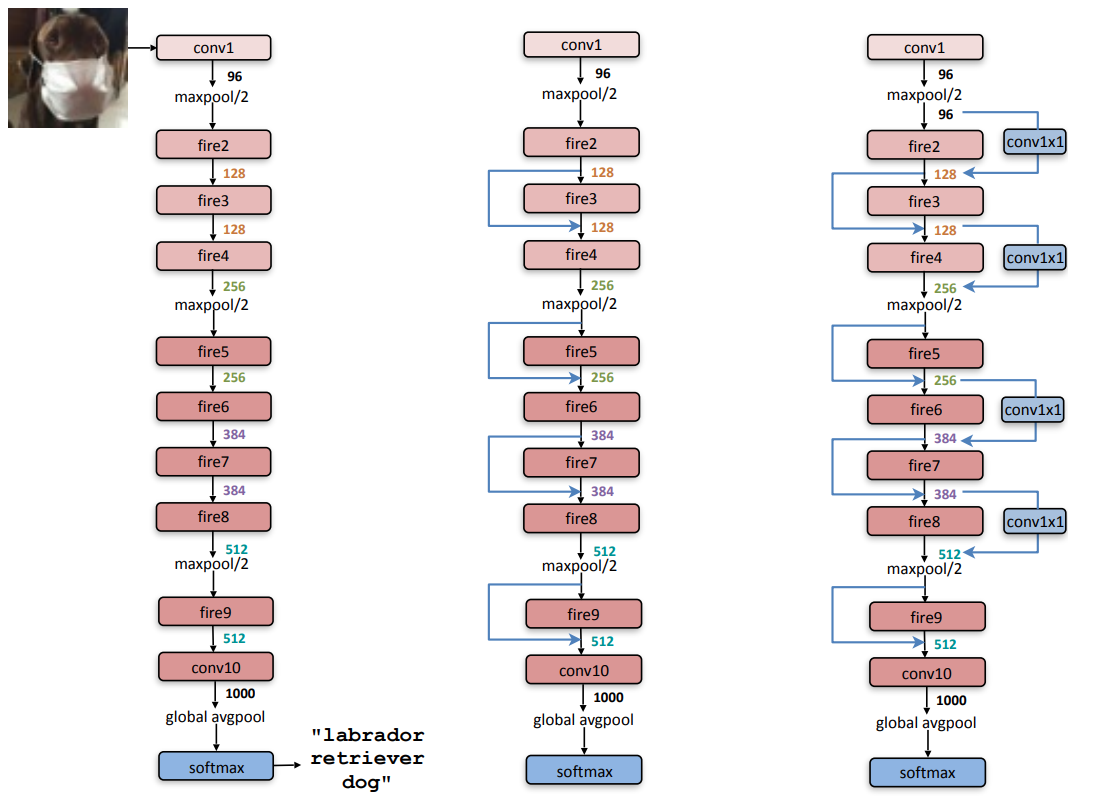
지난 포스트 마지막 부분에 첨부했던 모델 알고리즘 흐름도이다.
CVPR SqueezeNet 논문에 첨부된 알고리즘 흐름도이며, 해당 흐름도를 기준으로 코드를 작성하였다.
딥러닝 모델 설계를 위해 tensorflow backend를 사용하는 Keras를 활용했다.
아래 코드를 돌리기 위해 필요한 사진 데이터셋은 아래 링크에서 "catsAndDogsSmall" 폴더를 통째로 다운받아 활용할 수 있다.
underflow101/MLDL
Machine Learning & Deep Learning Source Code. Contribute to underflow101/MLDL development by creating an account on GitHub.
github.com
해당 코드를 실행하기 위한 Requirements는 아래와 같다.
# Requirements
# tensorflow-gpu 2.0.0
# nvidia-ml-py3 7.352.0
# Keras 2.3.1
# Keras-Applications 1.0.8
# Keras-Preprocessing 1.1.0
# matplotlib 3.1.3
# h5py 2.10.0만약 버전이 맞지 않거나, 부족한 패키지가 있다면 pip install을 통해 다운로드 받으면 된다.
(例: 만약 tensorflow-gpu가 2.1.0 버전이라면 $ pip install tensorflow-gpu==2.0.0 을 통해 다운그레이드할 수 있다.)
단, GPU CUDA를 활용하지 않고 CPU tensorflow로 돌려도 무관하긴 하다.
다만 딥러닝의 속도가 굉장히 느릴 것이다.
이외 환경은 다음과 같다.
(상이해도 소스 코드를 구동시키는 데에 아무런 문제가 없다.)
# System Environments
# OS : Ubuntu 18.04.4 LTS
# CPU : Intel i9-9900KF 8 cores 16 threads @3.60GHz
# RAM : 32GB
# GPU : NVIDIA GeFore RTX 2080Ti CUDA enabled
# CUDA : 10.0 version
소스 코드 실행 방법은 위 Requirements를 모두 맞춰준 후, (가상환경 설정으로 하면 편해진다)
위 데이터세트(고양이와 강아지 사진)와 아래 소스 코드를 모두 다운로드 받은 후, 소스 코드 2번 파일(imagePreprocess.py)에서 경로 설정을 개인 PC에 맞게 바꿔준 후, 터미널이나 파이썬 콘솔에서 아래의 명령어를 쳐주면 된다.
$ python imagePreprocess.pyOutput으로는 가중치(weights.h5) 파일 하나, 모델 최종(catsAndDogs.h5) 파일 하나가 생성되면 성공적인 것이다.
현재 설정으로는 무려 723,522개의 Parameter를 3.0MB라는 경이로운 사이즈로 학습시켜준다.
단, 1,000개의 training set으로는 아직 80% 정도의 accuracy밖에 나오지 않는 것은 흠이라고 볼 수 있다.
소스 코드
1. model.py (SqueezeNet 모델 설계 파일)
# SqueezeNet Model Source Code
# Dev. Dongwon Paek
# SqueezeNet Model Source Code
import h5py
import os, shutil
import matplotlib.pyplot as plt
from keras import backend
from keras.models import Model
from keras.layers import Add, Activation, Concatenate, Conv2D, Dropout
from keras.layers import Flatten, Input, GlobalAveragePooling2D, MaxPooling2D
# This is specific 1.1 version of SqueezeNet. (2.4x less computation according to paper)
# Stacking Layers of SqueezeNet
# nb stands for number
# input_shape : must have (width, height, dimension)
# nb_classes : total number of final categories
# dropout_rate : determines dropout rate after last fire_module. default is None
# compression : reduce the number of feature maps. Default is 1.0
# RETURENS Keras model instance(keras.models.Model())
def SqueezeNet(input_shape, nb_classes, dropout_rate=None, compression=1.0):
input_img = Input(shape=input_shape)
x = Conv2D(int(64 * compression), (3, 3), activation='relu', strides=(2, 2), padding='same', name='conv1')(input_img)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='maxpool1')(x)
x = fire_module(x, int(16 * compression), name='fire2')
x = fire_module(x, int(16 * compression), name='fire3')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='maxpool3')(x)
x = fire_module(x, int(32 * compression), name='fire4')
x = fire_module(x, int(32 * compression), name='fire5')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='maxpool5')(x)
x = fire_module(x, int(48 * compression), name='fire6')
x = fire_module(x, int(48 * compression), name='fire7')
x = fire_module(x, int(64 * compression), name='fire8')
x = fire_module(x, int(64 * compression), name='fire9')
if dropout_rate:
x = Dropout(dropout_rate)(x)
# Creating last conv10
x = output(x, nb_classes)
return Model(inputs=input_img, outputs=x)
# Create fire module for SqueezeNet
# x : input (keras.layers)
# nb_squeeze_filter : number of filters for Squeezing. Filter size of expanding is 4x of Squeezing filter size
# name : name of module
# RETURNS fire module x
def fire_module(x, nb_squeeze_filter, name, use_bypass=False):
nb_expand_filter = 4 * nb_squeeze_filter
squeeze = Conv2D(nb_squeeze_filter,(1, 1), activation='relu', padding='same', name='%s_squeeze'%name)(x)
expand_1x1 = Conv2D(nb_expand_filter, (1, 1), activation='relu', padding='same', name='%s_expand_1x1'%name)(squeeze)
expand_3x3 = Conv2D(nb_expand_filter, (3, 3), activation='relu', padding='same', name='%s_expand_3x3'%name)(squeeze)
if backend.image_data_format() == 'channels_last':
axis = -1
else:
axis = 1
x_ret = Concatenate(axis=axis, name='%s_concatenate'%name)([expand_1x1, expand_3x3])
if use_bypass:
x_ret = Add(name='%s_concatenate_bypass'%name)([x_ret, x])
return x_ret
def output(x, nb_classes):
x = Conv2D(nb_classes, (1, 1), strides=(1, 1), padding='valid', name='conv10')(x)
x = GlobalAveragePooling2D(name='avgpool10')(x)
x = Activation("softmax", name='softmax')(x)
return x2. imagePreprocess.py (이미지 전처리기와 SqueezeNet으로 고양이와 강아지를 training, validating 하는 소스 코드)
# SqueezeNet Model Source Code
# Dev. Dongwon Paek
# Image Preprocessing
import h5py
import os, shutil
import matplotlib.pyplot as plt
from keras.optimizers import SGD
from keras import layers, models, optimizers
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping, ModelCheckpoint
from model import SqueezeNet
###############################################################################
# Diretory Path Creation
# Can separate this code to different python file and just import to this
original_dataset_dir = '/home/bearpaek/data/datasets/catsAndDogs/train'
base_dir = '/home/bearpaek/data/datasets/catsAndDogsSmall'
try:
os.mkdir(base_dir)
except FileExistsError:
print("괜찮아요우")
total_dir = list()
train_dir = os.path.join(base_dir, 'train')
total_dir.append(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
total_dir.append(validation_dir)
test_dir = os.path.join(base_dir, 'test')
total_dir.append(test_dir)
train_cats_dir = os.path.join(train_dir, 'cats')
total_dir.append(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
total_dir.append(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
total_dir.append(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
total_dir.append(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
total_dir.append(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
total_dir.append(test_dogs_dir)
try:
for item in total_dir:
os.mkdir(item)
except:
print("괜찮아요우")
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
print("훈련용 고양이 이미지 전체 개수: ", len(os.listdir(train_cats_dir)))
print("훈련용 강아지 이미지 전체 개수: ", len(os.listdir(train_dogs_dir)))
print("검증용 고양이 이미지 전체 개수: ", len(os.listdir(validation_cats_dir)))
print("검증용 강아지 이미지 전체 개수: ", len(os.listdir(validation_dogs_dir)))
print("테스트용 고양이 이미지 전체 개수: ", len(os.listdir(test_cats_dir)))
print("테스트용 강아지 이미지 전체 개수: ", len(os.listdir(test_dogs_dir)))
########################################################################################
########################################################################################
# Start learning, as well as compiling model
sn = SqueezeNet(input_shape = (224, 224, 3), nb_classes=2)
sn.summary()
train_data_dir = '/home/bearpaek/data/datasets/catsAndDogsSmall/train'
validation_data_dir = '/home/bearpaek/data/datasets/catsAndDogsSmall/validation'
nb_train_samples = 2000
nb_validation_samples = 1000
nb_epoch = 500
nb_class = 2
width, height = 224, 224
sgd = SGD(lr=0.001, decay=0.0002, momentum=0.9, nesterov=True)
sn.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
# Generator
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
#train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(width, height),
batch_size=32,
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(width, height),
batch_size=32,
class_mode='categorical')
############################################################################
# Inlcude this Callback checkpoint if you want to make .h5 checkpoint files
# May slow your training
#early_stopping = EarlyStopping(monitor='val_loss', patience=3, verbose=0)
#checkpoint = ModelCheckpoint(
# 'weights.{epoch:02d}-{val_loss:.2f}.h5',
# monitor='val_loss',
# verbose=0,
# save_best_only=True,
# save_weights_only=True,
# mode='min',
# period=1)
###########################################################################
sn.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples#,
#callbacks=[checkpoint])
)
sn.save_weights('weights.h5')
sn.save('catsAndDogs.h5')
# End of Code
##########################################################################코드 설명
해당 소스 코드의 코드 중 Convolution Filter, Maxpooling, Fire Module 등 기본적인 부분은 지난 글과 이전 글에서 모두 설명하였으므로 넘어가도록 한다.
(만약 참고가 필요하면 아래 링크를 타고 가면 된다.)
1. CNN 기본 지식(Maxpooling, Filter, Stride 등)
[딥러닝] 합성곱 신경망, CNN(Convolutional Neural Network) - 1 (이론편)
배 경 우리는 AI 시대에 살고 있다. 거의 모든 제품에는 어떤 인공지능이 들어가 있고 어떤 기능을 해서 어떻게 삶을 윤택하게 하는지에 대해 논하고 있다. 그 중 가장 대표적인 인공지능 알고리즘이라고 한다면..
underflow101.tistory.com
2. SqueezeNet 기본 이론(모델, Fire Module 등)
[Keras] SqueezeNet Model (CNN) 이란? - 1 (이론편)
서 론 머신러닝, 혹은 딥러닝을 공부하다 보면 '모델'이라는 개념이 등장한다. 주로 석/박사를 졸업하고 현업으로 AI직군을 들어가면 모델 설계 업무를 주로하게 된다. 요즘 모델의 트렌드는 주로 Accuracy, 즉..
underflow101.tistory.com
위 정보를 제외하고, 위 소스 코드에서 가장 중요한 부분은 sn.compile() 부분과 sn.fit_generator() 부분이다.
- sn.compile() 부분(line 111)
- optimizer는 sgd로, loss는 categorical_crossentropy로, metrics는 accuracy로 설정했다.
이 때, optimizer의 sgd는 바로 윗 줄(line 110)에서 정의되는 변수인데,
sgd = SGD(lr=0.001, decay=0.0002, momentum=0.9, nesterov=True)위와 같다.
이를 이론적으로 파헤쳐보겠다.
우선 SGD는 keras 패키지에서 제공되는 optimizer 중 하나로, 경사하강법 중 하나이다.
경사하강법은 1차 근삿값 발견용 최적화 알고리즘인데, 기본 개념은 함수의 기울기(경사)를 구하여 기울기가 낮은 쪽으로 계속 이동시켜서 극값에 이를 때까지 반복시키는 것이다. (참고로 경사하강법은 대학 "자동제어공학" 수업에서 더 깊이 배울 수 있다.)
이는 머신러닝/딥러닝 프로그램에서는 가중치(weight)를 조절하는 방법으로 정확하게 가중치를 찾아가지만 가중치를 변경할 때마다 전체 데이터에 대해 미분해야 하므로 계산량이 매무 많고, 속도가 느리다. 추가적으로 최적의 해를 찾기 전까지는 학습을 멈출 수도 있다.
1. SGD (Stochastic Gradient Descent)
이 중, SGD는 Stochastic Gradient Descent의 약자로 확률적 경사하강법이다.
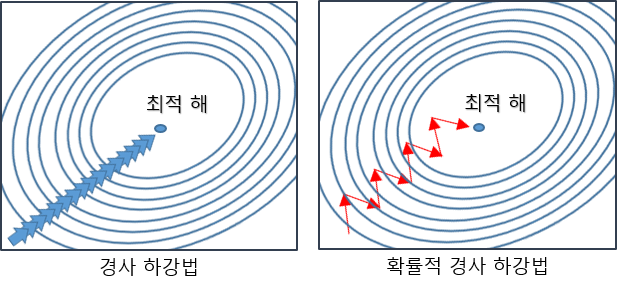
확률적 경사 하강법(SGD)는 경사하강법과는 다르게 한 번 학습할 때 모든 데이터에 대해 가중치를 조절하는 것이 아니라, 임의로 추출한 일부 데이터에 대해서만 가중치를 조절한다. 결과적으로 속도는 개선되었지만 최적해의 정확도는 낮게된다.
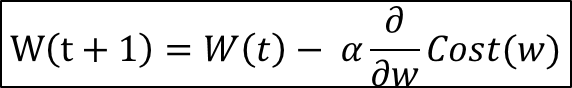
수식은 경사하강법과 같지만, Cost(w)에서 보다시피 입력 데이터 전체의 수가 아닌 확률적으로 선택된 부분이 사용된다.
α는 Learning Rate를 뜻하며, 소스 코드 첫 번째 인자인 "lr = 0.001"로 표기되었다.
2. Learning Rate Decay
위 수식에서는 생략되었지만, 소스 코드 두 번째 인자인 "decay = 0.0002"는 Learning Rate Decay를 의미한다.
머신러닝/딥러닝에서 SGD를 통한 Backprop를 할 때 weight의 Learning Rate를 잘 조정하는 것이 중요하다.
그리고 최적의 해를 구하기 위해서는 각 스텝(iteration/step)이 진행될 때마다 Learning Rate를 줄여야 하며, Learning Rate Decay는 이러한 Learning Rate를 각 스텝마다 줄여주는 역할을 한다.
decayed_learning_rate = learning_rate *
decay_rate ^ (global_step / decay_steps)
...
global_step = tf.Variable(0, trainable=False)
starter_learning_rate = 0.1
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
100000, 0.96, staircase=True)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)Tensorflow 코드에서는 Learning Rate Decay를 위와 같이 프로그래밍했다.
즉, 기존의 Learning Rate에 (Learning Rate Decay) ^ (Global_Step / Decay_step) 한 만큼 학습률이 줄어들게 되고, Global Step 내에서 경사하강법을 통해 가장 오차가 작은 곳을 찾는 방식으로 작동한다.
3. Momentum
물리학에서도 자주 찾아볼 수 있는 위 단어는 관성, 탄력이라는 뜻을 지닌다.
그렇기에, 해당 Optimizer에서도 Momentum은 SGD 경사하강법에 관성을 더해주게 된다.
SGD에 Momentum을 추가하게 되면, 경사하강법과 마찬가지로 매번 기울기를 구하지만, 가중치를 수정하기 전 수정 방향(±)를 참고하여 같은 방향으로 일정한 비율만 수정되기 한다.
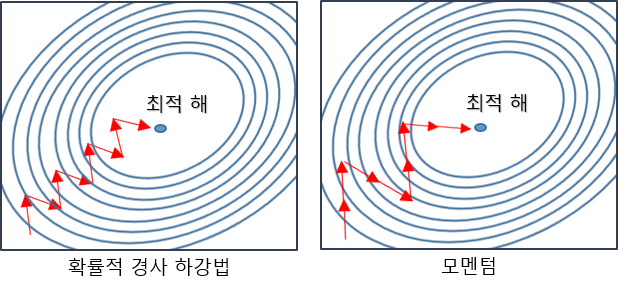
이로써 위 그림처럼 지그재그 현상이 줄고, 관성의 효과를 낼 수 있어 연산량이 줄어들게 된다.
수식은 아래와 같다.
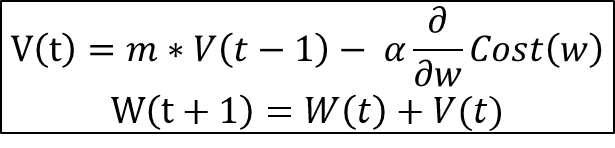
이 때, m이 Momentum 계수이다.
소스 코드에서는 세 번째 인자로 "momentum = 0.9"로 표기되었다.
4. Nesterov Accelerated Gradient (네스테로프 가속 경사)
Nesterov Accelerated Gradient는 Momentum값과 Gradient값이 더해져 Actual Value를 만드는 기존 Momentum과는 달리, Momentum이 적용된 시점에서 Gradient값이 계산되게 된다.
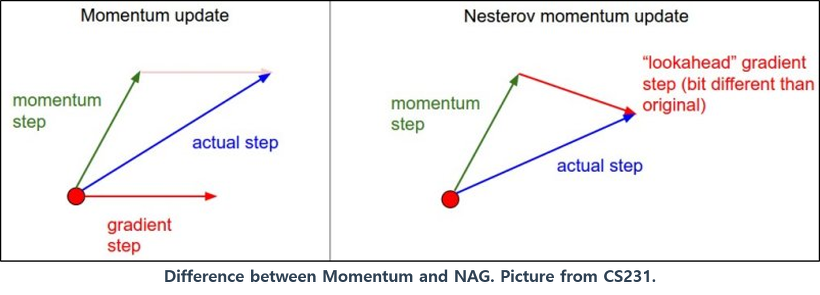
Nesterov Accelerated Gradient를 추가함으로써 V(t)를 계산하기 전 Momentum 방식으로 인해 이동될 방향을 미리 예측하고 해당 방향으로 얼마간 미리 이동한 뒤 Gradient를 계산하게 되므로, 불필요한 이동을 줄여 Accuracy를 높일 수 있다.
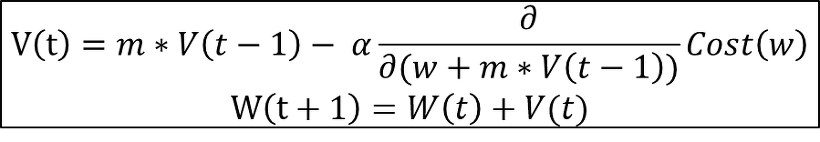
위 사진은 Nesterov Accelerated Gradient의 수식이며, 쉽게 알 수 있듯, 지금까지 나왔던 1, 2, 3, 4 단계의 모든 수식들이 종합되어있다.
- sn.fit_generator() 부분 (line 147)
- Model Training을 위한 epoch나 sample per epoch 등을 결정한다.
sn.fit_generator()는 위 sn.compile() 부분보다는 이해하기 용이하다.
sn.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples#,
#callbacks=[checkpoint])
)Model Training을 위해 경로는 미리 정의된 train_generator(line 123 ~ 127) 생성자를 이용하며, 각 epoch별 training sample 개수를 정해준다.
이 때, epoch는 인공 신경망(Neural Network)에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 뜻한다.
신경망에서 사용되는 역전파 알고리즘(Backpropagation Algorithm)은 parameter를 사용하여 input부터 output까지의 각 계층의 weight를 계산하는 과정을 거치는 forward pass,
이 방향을 반대로 거슬러 올라가며 다시 한 번 계산과정을 거쳐 weight를 보정하는 backward pass로 나뉘는데,
이 전체 데이터 셋에 대해 forward pass와 backward pass가 각각 완료되면 한 번의 epoch가 진행됐다고 볼 수 있다.
또한, nb_epoch로 총 epoch 수를 조절할 수 있다.
당연하지만, nb_epoch가 많을 수록 accuracy는 올라가지만(오버피팅으로 떨어질 수는 있으나, 대체로 떨어지다가도 올라간다. 데이터세트가 많으면 많을수록, nb_epoch가 높으면 높을수록 accuracy는 올라간다.) 그만큼 training이 현실적으로 오래 걸리게 된다.
그 다음에 있는 validation_generator 생성자는 검증을 하게 되어 training된 weight를 직접 적용해보는 것으로 accuracy를 확인한다.
맨 마지막에 주석 처리한 callbacks = [checkpoint]는 체크포인트 콜백을 위한 것으로,
만약 중간중간의 weight를 .h5 파일로 남겨 흔적을 분석해야 한다면 주석을 해제한 후, line 134 ~ 146까지의 주석까지 해제하면 된다.
대신 training에 걸리는 시간은 더 길어지게 된다.
결 론
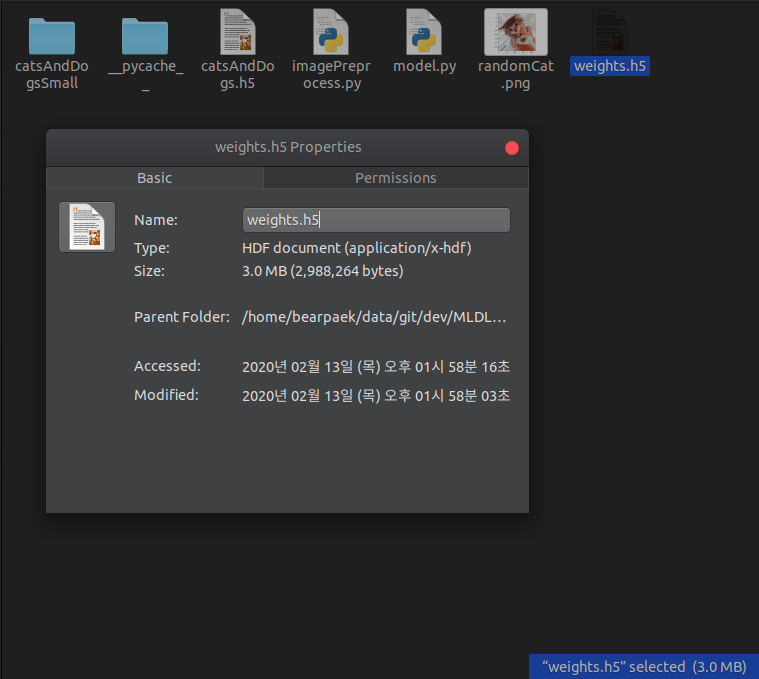
맨 위에서 예고되었듯, weight.h5 파일은 무려 3.0MB밖에 하지 않는다.
VGG16의 경우 weight.h5 파일이 500MB가 넘어가는 것을 생각하면, 정말 큰 차이가 아닐 수 없다.
보통 이러한 VGG16이나 Darknet의 모델들의 경우, 그 크기 때문에 라즈베리파이나 Small Computing Unit에 절대 홀로 동작시킬 수 없게 된다.
(물론 Intel의 Movidius 같은 NPU를 꽂으면 할 수는 있지만 비용적 이슈가 있다.)
그러나 SqueezeNet의 경우 충분히 라즈베리파이 같은 작은 MPU에도 적용시킬 수 있는 여지가 있다.
그렇다면 accuracy는 어떨까?
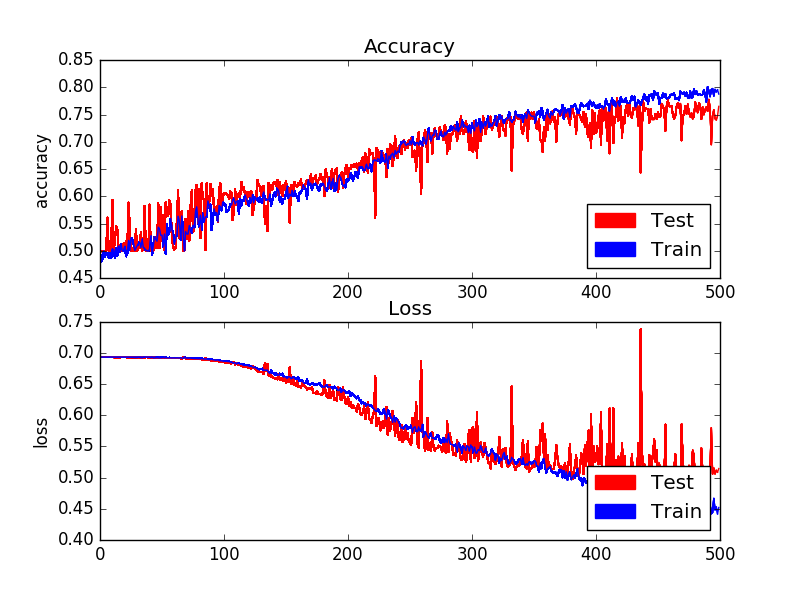
위 그래프에서 우리는 validation 사진 500개를 거치며 accuracy가 80%에 육박하게 되는 것을 알 수 있다.
하지만 80%는 높은 수치가 아니다. 최소 95%는 넘어야 실제 applicable한 모델이라고 할 수 있다.
그러나,
아무리 accuracy가 높다고 한들 비용적 이슈가 해결되지 않으면 결코 사용될 수 없는 것 또한 사실이다.
그렇기에 SqueezeNet은 낮은 cost와 초경량화된 모델로 적당한 accuracy를 갖는 모델이라고 접근해야한다.
정말 낮은 코스트의 임베디드 리눅스에서 반드시 딥러닝을 사용해야 하는데, 비용적, 혹은 성능적 제약이 극심할 때 사용할 수 있는 대안이라고 생각할 수 있을 것이다.
추 가

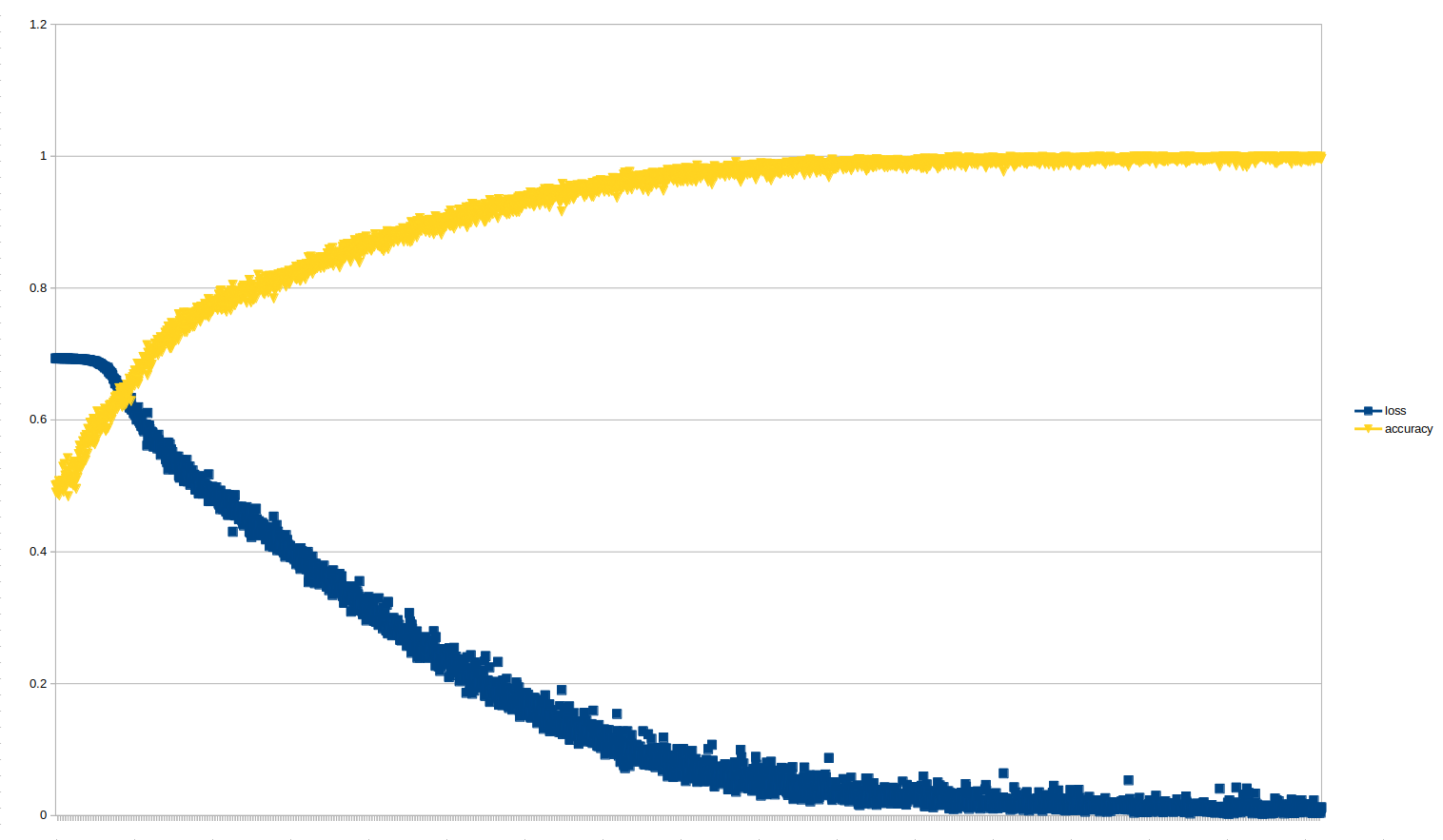
주말 내내 3,000 epochs를 돌리고 난 결과이다.
Accuracy 99.59%, Loss 1.2% 대이다.
모델의 weight.h5 파일은 당연하게도 여전히 3.0MB밖에 되지 않는다.
즉, 더 많은 데이터셋과 더 많은 시간을 들여 더 많은 epochs를 돌리면,
SqueezeNet은 적은 모델 weight 크기와 더불어 매우 높은 Accuracy와 매우 낮은 Loss를 보이는 굉장히 좋은 모델임을 확인할 수 있었다.
'AI & Big Data > AI' 카테고리의 다른 글
| [AI 이론] Layer, 레이어의 종류와 역할, 그리고 그 이론 - 2 (BatchNormalization) (2) | 2020.07.07 |
|---|---|
| [AI 이론] Layer, 레이어의 종류와 역할, 그리고 그 이론 - 1 (Conv2D) (2) | 2020.07.06 |
| [Keras] SqueezeNet Model (CNN) 이란? - 1 (이론편) (0) | 2020.02.12 |
| [딥러닝] 합성곱 신경망, CNN(Convolutional Neural Network) - 이론편 (0) | 2020.01.17 |
| [개념/이론] 주요 딥러닝 프레임워크 비교 (0) | 2019.12.06 |



