IT/자료구조
[Python] 더블 링크드 리스트 (이중 연결 리스트)
공대생의 차고
2019. 11. 30. 02:08
반응형
싱글 링크드 리스트를 배웠으면 더블 링크드 리스트를 빼먹을 수 없다.
(만약 지난 싱글 링크드 리스트가 궁금하다면? 2019/11/29 - [IT/자료구조] - [Python] 싱글 링크드 리스트 (단순 연결 리스트))
이 또한 워낙 방대한 자료가 많지만,
추후 그래프나 트리 구현을 할 때 제반 지식이 될 수 있도록 꼭 구현해보는 것을 추천한다.
기초적인 지식
1. 시간복잡도
| Double Linked List | ||
| 최선 | 최악 | |
| 삽입 | O(1) | O(1) |
| 삭제 | O(1) | O(1) |
| 탐색 | O(k) | O(k) [인덱스 탐색 시] O(N) [값 탐색 시] |
이전 포스트였던 싱글 링크드 리스트와는 다른 점이 있다면 탐색이다.
그리고 지난 싱글 링크드 리스트와 함정 또한 공유한다.
2. 장점
- 싱글 링크드 리스트와 모든 장점을 공유한다. (2019/11/29 - [IT/자료구조] - [Python] 싱글 링크드 리스트 (단순 연결 리스트) 글 참조)
3. 단점
- Random Access, 즉 배열처럼 index를 통해 탐색이 불가능하다.
- Index를 통해 순차 탐색을 할 경우, 최대 O(N/2) 혹은 O(k)의 시간복잡도가 걸린다.
- 아래 소스 코드를 보면 더블 링크드 리스트의 크기와 탐색하고자 하는 index의 크기를 비교하여 head와 tail 중 더 가까운 곳에서 탐색을 시작한다.
- 그러므로 싱글 링크드 리스트에 비해 가지는 장점은 탐색이 최대 2배 더 빠르므로, 삽입과 삭제 또한 그만큼 빠르다.
그래도 배열보다 느리다.
- Value(값)를 통해 순차 탐색을 할 경우, 싱글 링크드 리스트와 마찬가지로 O(N)의 시간복잡도가 걸린다. (단, 현재 소스 코드에서는 Value를 통한 탐색은 구현하지 않았다.)
4. 결론
파이썬의 리스트를 사용하자- 추후 트리나 그래프를 위해 미리 공부한다는 느낌으로 노드의 움직임을 이론적으로 이해하려고 노력하는 자세가 제일 중요할 것 같다.
더블 링크드 리스트의 구조도
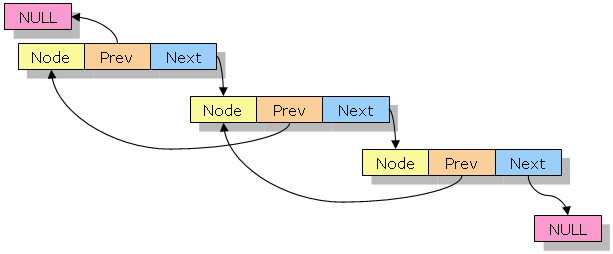
반응형
소스 코드
#Double Linked List
class Node(object):
def __init__(self, data, prev = None, next = None):
self.data = data
self.prev = prev
self.next = next
class DList(object):
def __init__(self):
self.head = Node(None)
self.tail = Node(None, self.head)
self.head.next = self.tail
self.size = 0
def listSize(self):
return self.size
def is_empty(self):
if self.size != 0:
return False
else:
return True
def selectNode(self, idx):
if idx > self.size:
print("Overflow: Index Error")
return None
if idx == 0:
return self.head
if idx == self.size:
return self.tail
if idx <= self.size//2:
target = self.head
for _ in range(idx):
target = target.next
return target
else:
target = self.tail
for _ in range(self.size - idx):
target = target.prev
return target
def appendleft(self, value):
if self.is_empty():
self.head = Node(value)
self.tail = Node(None, self.head)
self.head.next = self.tail
else:
tmp = self.head
self.head = Node(value, None, self.head)
tmp.prev = self.head
self.size += 1
def append(self, value):
if self.is_empty():
self.head = Node(value)
self.tail = Node(None, self.head)
self.head.next = self.tail
else:
tmp = self.tail.prev
newNode = Node(value, tmp, self.tail)
tmp.next = newNode
self.tail.prev = newNode
self.size += 1
def insert(self, value, idx):
if self.is_empty():
self.head = Node(value)
self.tail = Node(None, self.head)
self.head.next = self.tail
else:
tmp = self.selectNode(idx)
if tmp == None:
return
if tmp == self.head:
self.appendleft(value)
elif tmp == self.tail:
self.append(value)
else:
tmp_prev = tmp.prev
newNode = Node(value, tmp_prev, tmp)
tmp_prev.next = newNode
tmp.prev = newNode
self.size += 1
def delete(self, idx):
if self.is_empty():
print("Underflow Error")
return
else:
tmp = self.selectNode(idx)
if tmp == None:
return
elif tmp == self.head:
tmp = self.head
self.head = self.head.next
elif tmp == self.tail:
tmp = self.tail
self.tail = self.tail.prev
else:
tmp.prev.next = tmp.next
tmp.next.prev = tmp.prev
del(tmp)
self.size -= 1
def printlist(self):
target = self.head
while target != self.tail:
if target.next != self.tail:
print(target.data, '<=> ', end='')
else:
print(target.data)
target = target.next싱글 링크드 리스트를 심도 있게 공부해보았다면 전혀 어렵지 않은 코드이다.
물론 소스 코드의 길이는 더 길어졌지만, 결국 next와 prev 포인터를 함께 저장하기 위해 길어진 것일 뿐, 개념적으로는 앞과 뒤가 함께 있다는 것 외에는 동일하다.
이 소스 코드를 지난 싱글 링크드 리스트와 같은 예제를 넣어주면 과연 그때와 같은 결과가 나올까?
한 번 넣어보자.
mylist = DList()
mylist.append('A')
mylist.printlist()
mylist.append('B')
mylist.printlist()
mylist.append('C')
mylist.printlist()
mylist.insert('D', 1)
mylist.printlist()
mylist.appendleft('E')
mylist.printlist()
print(mylist.listSize())
mylist.delete(0)
mylist.printlist()
mylist.delete(3)
mylist.printlist()
mylist.delete(0)
mylist.printlist()
mylist.appendleft('A')
mylist.printlist()위와 같이 실행해보면,
A
A <=> B
A <=> B <=> C
A <=> D <=> B <=> C
E <=> A <=> D <=> B <=> C
5
A <=> D <=> B <=> C
A <=> D <=> B
D <=> B
A <=> D <=> B결과가 (화살표 모양만 빼고) 싱글 링크드 리스트 때와 동일하게 나온다.
당연히 그래야 한다.
그러니 혹시 혼자 구현해보다가 결과가 다르게 나온다면 코드를 다시 짜보기를 권장한다.
기본은 힘!
반드시 익혀두도록 하자.
반응형